
Forecasting with Neural Networks - An Introduction to Sequence-to-Sequence Modeling Of Time Series
Note: if you’re interested in building seq2seq time series models yourself using keras, check out the introductory notebook that I’ve posted on github.
Using data from the past to try to get a glimpse into the future has been around since humans have been, and should only become increasingly prevalent as computational and data resources expand. Companies can use forecasting methods to anticipate trends that are core to their business, improving their decision making and resource allocation. Examples abound: grocery chains and online retailers predict product demand for inventory stocking, popular websites predict page visits to manage server demand, and rideshare apps predict trip volume by area to distribute their drivers more effectively.
These diverse applications share a common quantitative framework under the umbrella of time series forecasting. Each unit of interest (item, webpage, location) has a regularly measured value (purchases, visits, rides) that changes over time, giving rise to a large collection of time series.
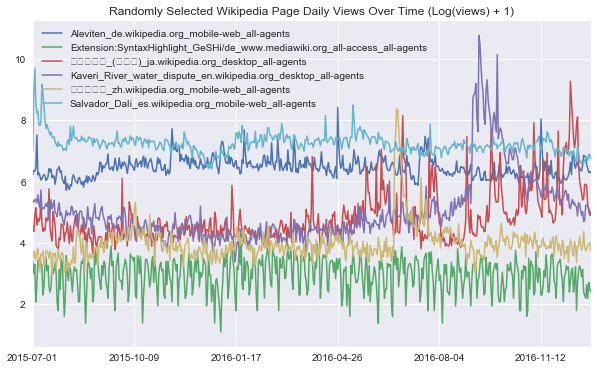
In traditional time series forecasting, series are often considered on an individual basis, and predictive models are then fit with series-specific parameters. An example of this style is the classic Autoregressive Integrated Moving Average (ARIMA) model. Series-specific models can often make quite good predictions, but unfortunately they do not scale well to problems where the number of series to forecast extends to thousands or even hundreds of thousands of series. Additionally, fitting series-specific models fails to capture the expressive general patterns that can be learned from studying many fundamentally related series. From the examples above, we can see that this challenging “high-dimensional” time series setting is faced by many companies.
Luckily, multi-step time series forecasting can be expressed as a sequence-to-sequence supervised prediction problem, a framework amenable to modern neural network models. At the cost of added complexity in constructing and tuning the model, it’s possible to capture the entire predictive problem across all the series with one model. Since neural networks are natural feature learners, it’s also possible to take a minimalistic approach to feature engineering when preparing the model. And when exogenous variables do need to be integrated into the model (e.g. product category, website language, day of week, etc.), it’s simple due to the flexibility of neural network architectures. If you’re not already sold on the potential power of this approach, check out the DeepAR model that Amazon uses to forecast demand across a massive quantity of products.
So how does seq2seq work exactly? I’ll give a high level description. Let’s first consider it in its original application domain as described by this 2014 paper, machine translation. Here’s a visualization summary, taken from Fariz Rahman’s repo –
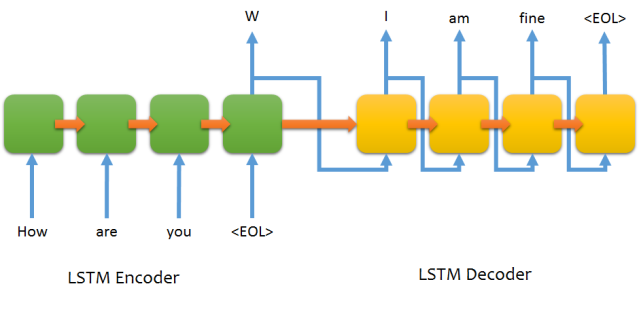
The model uses an “encoder-decoder” framework, mapping an arbitrarily long input sequence to an arbitrarily long output sequence with an intermediate encoded state. You can think of the encoded state as a representation of the entire history of the sequence that provides the context the decoder needs to generate an output sequence. In this case, the encoded state stores the neural network’s “understanding” of the sentence it’s read. This understanding is produced by iteratively “reading” each of the input words using an LSTM architecture (or similar type of recurrent neural network), which produces the final state vectors that give the encoding. The decoder LSTM then takes these encoded state vectors for its initial state, iteratively “writing” each output and updating its internal state.
Note that only some of the language I just used was specific to NLP – we can replace “word” with “token” or “value”, and easily generalize to sequences from many problem domains. In particular, we can move from mapping between input and output sentences to mapping between time series. In time series forecasting, what we do is translate the past into the future. We encode the entire history of a series including useful patterns like seasonality and trend, conditioning on this encoding to make future predictions.
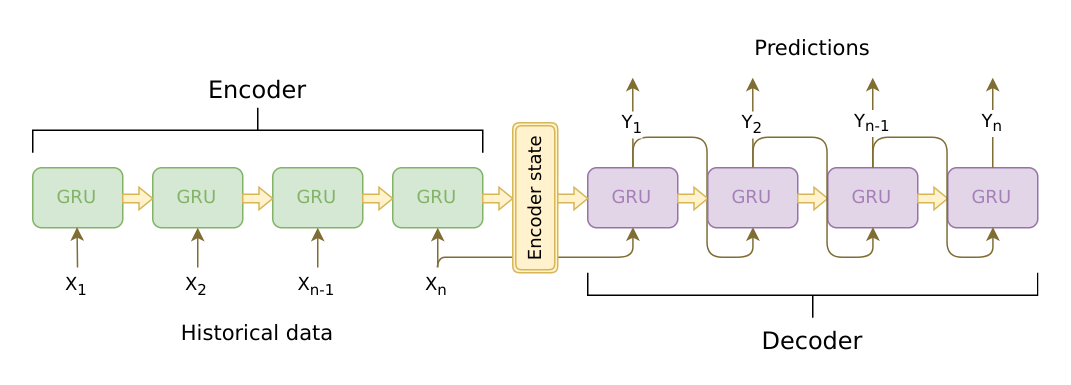
To clarify this further, here’s an excellent visual from Artur Suilin. I highly recommend checking out his repo with a state of the art time series seq2seq tensorflow model if you’re interested in this subject.
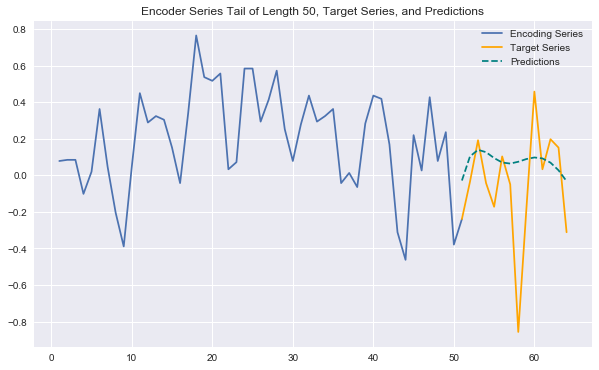
As a proof of concept, let’s see a basic version of this model be applied to a real dataset - daily wikipedia webpage traffic. If you’re interested in recreating this yourself, you can use the accompanying notebook I’ve written. The plot below shows predictions generated by a seq2seq model for an encoder/target series pair within a time range that the model was not trained on (shifted forward vs. training time range). Clearly these are not the best predictions, but the model is definitely able to pick up on trends in the data, without the use of any feature engineering.
Stay tuned for more on alternative and fancier architectures for this seq2seq problem, and increasingly predictive models.